

Desinformation und Meinung
Die Grundlage für eine starke und lebendige Demokratie ist eine informierte Bevölkerung. Leider genügt allein der Zugang zu Informationen nicht aus. Nachrichten und Inhalte müssen eingeordnet und in ihrer Vertrauenswürdigkeit bewertet werden. Aus den vertrauenswürdigen Informationen müssen wir uns schließlich unsere eigene Meinung bilden. Nachrichtenkompetenz und Meinungsbildungskompetenz zu erlangen, ist ein lebenslanger Lernprozess. Wichtige Grundlagen für diese Fähigkeiten werden schon in der Kindheit und Jugend angelegt. Im Folgenden zeigen wir, wie Sie Jugendliche dabei unterstützen können, Informationen zu bewerten und sich eine eigene Meinung zu bilden.

Das klicksafe-Handbuch „Ethik macht klick. Meinungsbildung in der digitalen Welt“ gibt Einblicke in das Informationsverhalten von Jugendlichen, bietet Hilfestellung beim Analysieren und Erkennen von Desinformationsstrategien und zeigt Auswirkungen von Falschinformation für die demokratische Gesellschaft auf. Die Zusatzmaterialien (Kopiervorlagen, Soundcollage, Wortsammlung) finden Sie mit Klick auf das Bild oben zum Download.
Wie informieren sich Jugendliche heute?
Jugendliche wachsen im 21. Jahrhundert in einer Welt auf, in der sie einfach und direkt Zugang zu einer Fülle von Informationen haben. Über ihr Smartphone und soziale Medien wie YouTube, Facebook, Twitter und Instagram können sie Informationen jederzeit und überall nicht nur empfangen, sondern auch bewerten und teilen oder selbst Mitteilungen erstellen und dabei direkt in den Diskurs mit anderen eintreten.
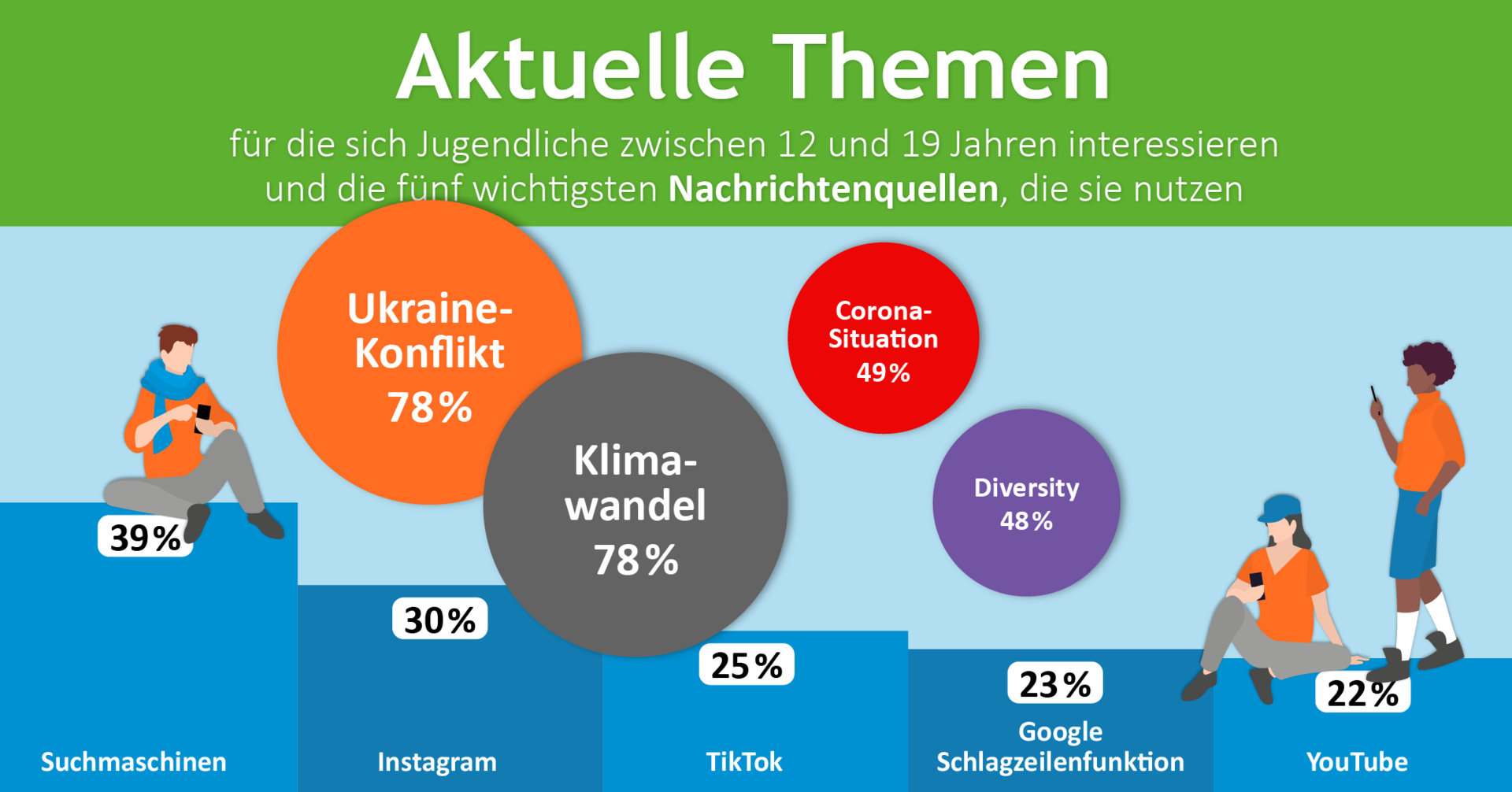
Auf der Suche nach Informationen nutzt ein Großteil der 12- bis 19-Jährigen in erster Linie Suchmaschinen (bspw. für das Googeln nach Begriffen). Auch YouTube und Online-Enzyklopädien, wie Wikipedia, sind Anlaufstelle bei der Informationssuche. Journalistische Angebote wie Nachrichtenportale von Zeitungen, Zeitschriften oder TV-Sendern sind für Jugendliche weniger relevant. Erst mit zunehmendem Alter werden diese Angebote als Informationsquelle wichtiger.
In sozialen Medien kommen jugendliche Internetnutzer*innen eher beiläufig und zufällig in Kontakt mit Nachrichten. Sie fühlen sich dadurch ausreichend über aktuelle Ereignisse in Deutschland und der Welt informiert. Nachrichten im klassischen Sinne nehmen nur einen geringen Stellenwert im Alltag junger Menschen ein.
In einer digitalisierten Öffentlichkeit haben sich die Menge und das Spektrum der verfügbaren Informationen deutlich vergrößert. Die Vielfalt kann für Jugendliche auch bedeuten, dass sie unbeabsichtigt mit Angeboten konfrontiert werden, die extremistischer Natur sind, verschwörungstheoretische Positionen vertreten oder Teil staatlicher Desinformationskampagnen sind. Es kommt zu einer Konkurrenz verschiedener Akteure, die auf die (politische) Meinungsbildung Jugendlicher einwirken und um ihre Aufmerksamkeit werben. Die Beurteilung einer Information hinsichtlich ihres Wahrheitsgehaltes wird für Jugendliche dadurch komplizierter.
Infos aus dem Netz – ist das ein Problem?
In der Adoleszenz durchlaufenen Jugendliche Entwicklungsphasen, in denen sich die Persönlichkeit und die Identität bilden. Hierzu gehören auch weltanschauliche Positionen und politische Meinungen. Die (politische) Sozialisation von Jugendlichen findet mittlerweile auch im Internet und über die sozialen Medien statt. Neben den Informations- und Nachrichtenangeboten spielen hier auch die Kommunikation über Messenger-Dienste und der Austausch in den sozialen Netzwerken eine zentrale Rolle.
In den sozialen Medien vermischen sich die öffentliche und die private Kommunikation. Sie schaffen eine neue Kommunikationsebene zwischen klassischen Massenmedien und der direkten Interaktion. Die Meinungsbildung Jugendlicher orientiert sich stark an ihrem sozialen Umfeld und der Peergroup, mit der sie auch permanent online verbunden sind.
Bandwagon Heuristic
In sozialen Netzwerken sind neben den Algorithmen vor allem Freunde und Bekannte die Gatekeeper zu den Informationen. Erreichen eine*n Nutzer*in Nachrichten über bekannte soziale Kontakte, erhöht dies tendenziell das Vertrauen in die Information. Die meisten Menschen halten Aussagen und Empfehlungen aus ihrem persönlichen Umfeld für glaubwürdig, egal ob im direkten Gespräch oder über soziale Netzwerke. Insbesondere wenn die Verbreiter*innen als sympathisch und kompetent wahrgenommen werden. Dieser Effekt, dass etwas, das von anderen als gut befunden wird, von einem selbst auch als gut beurteilt werden kann, wird als Bandwagon Heuristic beschrieben. Für das Vertrauen in inkorrekte Informationen kann dieser Effekt als möglicher Erklärungsansatz herangezogen werden.
Verunsicherung durch Desinformation
Gerade jüngere Menschen, deren Weltbilder sich erst formen, können durch Manipulationsstrategien und Desinformation nachhaltig beeinflusst werden. Während Jugendliche mit höherer Bildung mit den Angeboten im Internet in der Regel reflektiert umgehen können, sind besonders Jugendliche mit einem geringen Bildungsgrad gefährdet. Sie können problematische Weltbilder entwickeln, die demokratischen Grundideen entgegenstehen. Etwa ein Glaube an heimliche Eliten, die im Hintergrund „die Fäden ziehen“. Die Shell Jugendstudie 2019 hat ermittelt, dass in dieser Gruppe Jugendlicher fast jede zweite Person populistischen Positionen zuneigt. Neben lebensweltlichen Gründen und dem Gefühl der Benachteiligung verstärken soziale Medien diese Tendenz.
Confirmation Bias
Ob wir etwas glauben und für möglich halten, hängt davon ab, welche Überzeugungen und Vorstellungen wir haben. Neue Informationen, die zu unseren Glaubensgrundsätzen passen, werden in unsere Vorstellungswelt integriert und für wahr gehalten. Begegnen wir Informationen, die nicht in unser Überzeugungssystem passen, erleben wir mentalen Stress. Um den Widerspruch auszugleichen, halten wir nur die Information für glaubwürdig, die unsere Meinungen bekräftigt, auch wenn sie falsch oder manipulativ eingesetzt sein sollte. Je geschlossener und einfacher ein Weltbild ist, umso eher entfaltet der Bestätigungsfehler seine Wirkung.
Tipps für Eltern und pädagogische Fachkräfte
Junge Menschen sind häufig in sozialen Netzwerken unterwegs und informieren sich online. Dabei können sie die Glaubwürdigkeit von Informationen nicht immer richtig einschätzen. Ihnen fehlt oft das nötige Vorwissen, um Widersprüche zu erkennen. Außerdem neigen sie noch mehr als Erwachsene dazu, Menschen zu vertrauen, die sie kennen – wenn auch nur aus dem Internet.
Um sich eine gesicherte Meinung zu bilden, braucht man jedoch Tatsachen und Fakten statt manipulierter Bilder, Videos oder erfundener Schlagzeilen. Deshalb ist es wichtig, dass auch Erziehungsberechtigte das Thema Desinformation altersgerecht mit ihnen besprechen und deutlich machen, dass es irreführende Nachrichten im Netz gibt. Aufklärung hilft dabei, die Verbreitung von Falschnachrichten zu stoppen.
Es ist wichtig, Kinder darüber aufzuklären, dass es in der bunten Onlinewelt auch auf Desinformationen und Falschnachrichten stoßen kann. Dabei hilft es, wenn Sie schon sehr früh anfangen, mit Ihrem Kind darüber zu sprechen und deutlich zu machen, dass nicht alles, was im Internet steht, wahr ist. Es sollte klar gemacht werden, dass es Menschen gibt, die gezielt falsche Informationen (Desinformationen und/oder Verschwörungsideologien) verbreiten, um damit Geld zu verdienen oder Meinungen zu beeinflussen. Ein gesundes Misstrauen im Umgang mit Informationen ist also wichtig. So lernt Ihr Kind, Meinungen und Nachrichten einzuordnen und zu hinterfragen.
- klicksafe-Quiz für Jugendliche zum Thema Fake News und Verschwörungstheorien
- Actionbound-Spiel von klicksafe für Jugendliche „Im Bunker der Lügen“
- Infobroschüre für Eltern und Pädagog*innen: "Vertraust du noch oder checkst du schon?"
- Familien-Checkliste zum Thema Falschmeldungen
- SWR Fakefinder (ab 14 Jahren), SWR Fakefinder Kids (ab 8 Jahren)
- Lernmodul für Kinder im Grundschulalter zum Internet-ABC
Thematisieren Sie mit Kindern und Jugendlichen das Weltgeschehen und tauschen Sie sich über verschiedene Meinungen und Nachrichtenquellen aus. Über aktuelle Debatten, zum Beispiel zur Coronapandemie, können Sie sich den Themen nähern. Besonders in unsicheren Zeiten sind Sie wichtige Gesprächspartner*innen.
Weil sie wie vertrauenswürdige Nachrichten aussehen, sich aufregend lesen und oft schockieren, verbreiten sich Falschmeldungen rasend schnell. Den Unterschied zwischen wahr und falsch auf den ersten Blick zu erkennen und Informationen zu filtern: Bei der Informationsflut im Netz fällt das schon Erwachsenen schwer. Noch schwerer ist es für junge Menschen und Kinder. Folgende Punkte können dabei helfen, Falschnachrichten zu entlarven:
Reißerische Überschriften kritisch beleuchten: Schockiert die Überschrift? Ist sie überraschend und sorgt für große Emotionen wie Angst oder Hass? Was direkt unglaubwürdig scheint, ist es oft auch.
Kritisch sein und Quelle prüfen: Woher kommt die Information? Ist nachvollziehbar, wer die Nachricht herausgegeben oder verfasst hat? Sind im Impressum Name und Adresse angegeben? Ein Blick auf die Autorenschaft oder ins Impressum einer Website zeigt normalerweise, wer hinter dem Inhalt steht. Sind sie parteilich? Kennen sie sich aus? Welche Absichten verfolgen sie?
Fakten checken: Stimmt, was behauptet wird? Ist die Information wirklich korrekt? Haben andere, vertrauenswürdige Nachrichtenquellen dieselbe Meldung veröffentlicht? Vorsicht bei Texten, die vor allem auf die Schlagzeile reduziert sind und außerdem viel Meinung und wenig Inhalt präsentieren. Wenn die Überschrift in der Suchmaschine keine Treffer von anderen (seriösen) Medien findet, ist die Meldung wahrscheinlich frei erfunden. Die Recherche erleichtern spezielle Faktenchecker wie Mimikama.at, CORRECTIV, ARD-Faktenfinder und Hoaxmap. Das Suchwort einfach dort eingeben.
Auf die Aktualität achten: Wie aktuell sind die Informationen? Gerade bei wissenschaftlichen Studien, Umfragen oder Statistiken muss man darauf achten, dass die Informationen nicht allzu veraltet und womöglich schon längst überholt sind. In Suchmaschinen hilft ein voreingestellter Filter, der den Zeitraum der Ergebnisse einschränkt, die neusten Informationen zu einem Thema zu finden.
Bild oder Video unter die Lupe nehmen: Was ist zu sehen? Woher stammt das Bild oder Video? Sieht es unglaubwürdig aus, oder wurde es aus dem Zusammenhang gerissen? Für die Rückwärtssuche von Bildern eignet sich Google am Computer. Auf Smartphones und Tablets hilft zum Beispiel die App TinEye.
Aktiv werden: Falschmeldungen auf der Plattform melden oder Faktenchecker*innen kontaktieren.
Nicht ungeprüft weiterleiten: Nachrichten nicht leichtfertig teilen, hier gilt: Erst Fakten checken und Quelle prüfen — dann weiterleiten.
Nicht ignorieren: Die Weiterleitenden respektvoll darauf aufmerksam machen, wenn sie Falschmeldungen verbreiten. Vielleicht haben sie nicht gewusst, dass der Inhalt von einer unseriösen Quelle stammt.
Gekonnt kontern: Zum Beispiel durch das Posten von lustigen Memes. Oder andere Nutzer*innen, die widersprechen, mit einem Like unterstützen. Aber Vorsicht: Manche Themen können die Gemüter in einer Diskussion stark aufheizen. Solche Streitgespräche sind wenig zielführend.
Über Kindersuchmaschinen wie Blinde Kuh oder fragFinn finden Kinder gute Angebote, um sich altersgerecht zu informieren. Für Grundschulkinder bieten sich spezielle Nachrichtenangebote an wie beispielsweise ZDF logo! oder Kruschel. Älteren Kindern kann man verschiedene, seriöse Nachrichtenseiten zeigen, damit sie Meldungen vergleichen können, wenn sie unsicher sind.
Faktenchecker-Angebote wie Mimikama.at, ARD-Faktenfinder oder CORRECTIV helfen beim Entlarven von Falschnachrichten.